![[C#.Net] FirstOrDefault ou SingleOrDefault -2](https://www.5degres.com/wp-content/uploads/2024/10/C.Net-FirstOrDefault-ou-SingleOrDefault-2.png)
Introduction
En tant que Développeurs, ne nous sommes-nous pas tous déjà posé la question d’utiliser un FirstOrDefault ou un SingleOrDefault ?
Si vous êtes un jeune Développeurs, il est probable que vous ayez rapidement balayé cette question d’un revers de la main en vous disant que dans l’immense majorité des cas, ce bon vieux FirstOrDefault fait le job car « qui peut le plus, peut le moins ».
A l’inverse, certains Développeurs, par un automatisme acquis lors de leur formation ou par conviction personnelle, utilisent le SingleOrDefault lorsque l’élément à identifier est effectivement censé être unique.
Mais qu’en est-il réellement ?
Un peu de sémantique
FirstOrDefault
Méthode Linq qui :
Retourne le premier élément d’une séquence ou une valeur par défaut si ladite séquence ne contient aucun élément.
Source : Microsoft Learn
En résumé, cette méthode permet de parcourir une collection et d’en extraire le premier élément correspondant au prédicat spécifié (ou la première entrée si absence de prédicat), ou une valeur par défaut si aucune correspondance avec le prédicat n’est identifiée.
SingleOrDefault
Méthode Linq qui :
Retourne un élément spécifique unique d’une séquence, ou une valeur par défaut si cet élément est introuvable.
Source : Microsoft Learn
En résumé, cette méthode permet de parcourir une collection et d’en extraire l’unique élément correspondant au prédicat spécifié, ou une valeur par défaut si aucune correspondance avec le prédicat n’est identifiée.
En pratique, quelle(s) différence(s) ?
Fonctionnement général
Théoriquement, le SingleOrDefault serait à privilégier dans le cas où il est sûr et certain que le prédicat recherché est unique dans la collection parcourue.
Pour s’en assurer, la méthode va donc parcourir l’ensemble de la collection même si le prédicat est identifié en cours de traitement.
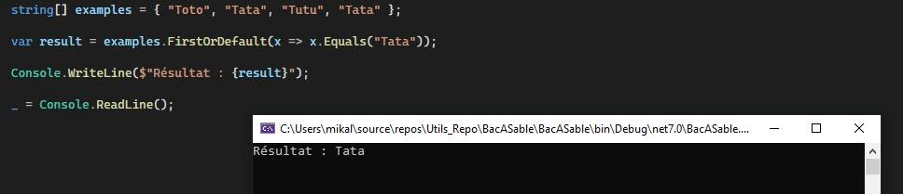
De son côté, le FirstOrDefault interrompt son action dès qu’il identifie l’objet de la recherche.
Que se passe-t-il donc s’il existe, malgré tout, plus d’une correspondance dans la collection parcourue ?
Dans le cas du SingleOrDefault, c’est très simple : une Exception est levée car cette situation n’est pas censée se produire.
Concernant le FirstOrDefault, peu importe pour lui qu’il existe plusieurs correspondances, dès qu’il en rencontre une, il la retourne.
Une image valant milles mots.
FirstOrDefault :
SingleOrDefault :
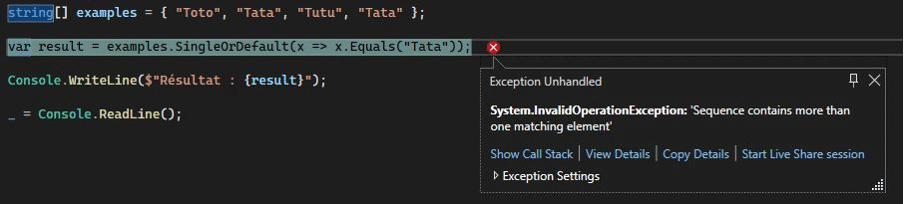
Il est essentiel de garder à l’esprit qu’il existe un risque associé à l’utilisation du SingleOrDefault, selon les éléments présents dans la collection source. Il est donc préférable de bien comprendre son usage et de prévoir ce cas de figure dans votre code pour garantir sa robustesse.
“Oui mais Jamy, si le Single est proposé c’est qu’il doit être plus efficace/optimisé quand on l’utilise dans les conditions prévues, non ?”
Dans les faits, cela n’est pas aussi simple …
Perfomances
Comme indiqué plus haut, par essence, le SingleOrDefault parcourt l’entièreté de la collection avant de retourner un résultat … Ou une Exception.
Le FirstOrDefault ne se donne pas cette peine.
Comment cela se traduit-il en termes de délais de traitement et d’utilisation de mémoire ?
Est-ce négligeable ou à prendre en compte au moment du développement ?
Voyons cela au travers d’un petit Benchmark* :
Protocole
- Nous allons créer des collections de tailles différentes (100, 10 000, 1 000 000) => Les bottes de foin.
- Pour chaque collection, nous allons insérer un élément unique, qui sera celui visé par notre prédicat => L’aiguille.
- Pour chaque botte de foin, l’aiguille sera insérée à des positions différentes (première, milieu, dernière).
- Nous allons ensuite mesurer le temps nécessaire et la mémoire utilisée pour extraire l’aiguille des différentes bottes de foin par le FirstOrDefault et le SingleOrDefault.
Résultats
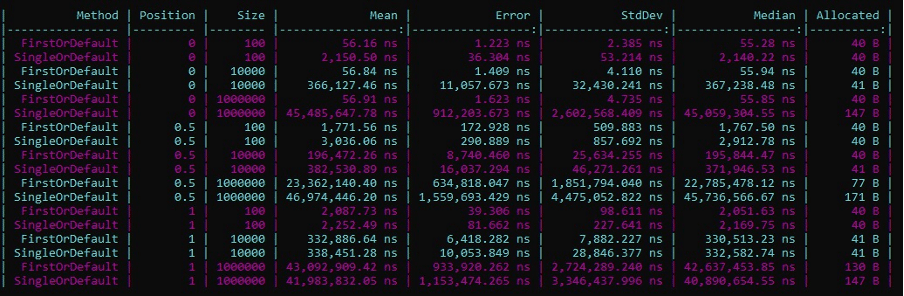
- Position : 0 (première entrée de la collection), 0.5 (milieu), 1 (dernière entrée de la collection)
- Size : Taille de la collection
- Mean : Durée du traitement
- Allocated : Mémoire allouée au traitement
Observations
Comme nous le constatons dans le tableau, dans quasiment tous les cas, le FirstOrDefault l’emporte en termes de délais d’exécution.
La durée du traitement est sensiblement la même dans le cas où l’élément à identifier est le dernier de la collection. Cela fait sens, puisque c’est le seul cas dans lequel le FirstOrDefault est obligé de la parcourir lui aussi en intégralité.
Nous pouvons d’ailleurs noter que plus l’ordre de grandeur de la collection augmente, plus l’écart de temps de traitement est conséquent entre les deux méthodes.
Concernant la consommation de mémoire nous constatons que les deux traitements sont similaires sauf lorsque l’ordre de grandeur de la collection est très élevé (1 000 000 dans notre test). Dans ce cas, c’est le SingleOrDefault qui consomme davantage que son homologue.
Conclusion
En conclusion, la sanction est assez nette. A part dans un cas précis, le FirstOrDefault est totalement avantageux en termes de temps d’exécution et d’économie de ressources.
Par ailleurs, le risque que représente la levée d’Exception du SingleOrDefault semble placer son « rival » comme choix par défaut.
Pour autant, si parmi vous certains ont eu des expériences ou des situations qui suggèrent davantage le recours au SingleOrDefault plutôt qu’au FirstOrDefault, n’hésitez pas à nous en faire part pour échanger.
Par ailleurs, il est important de garder à l’esprit que .Net Core est en perpétuelle évolution. Les requêtes Linq, notamment, subissent de gros changements depuis plusieurs versions. Il est donc possible qu’à l’avenir certains des points relevés doivent être mis à jour.
Pour toutes questions sur ce sujet, je me tiens à votre disposition.
(*) : BenchmarkDotNet est une bibliothèque .Net (package Nuget) dédiée à la mesure de performances

Michaël LESTAVEL
Consultant SI (spécialisé .Net)



