
Les petits modèles de langage : entre vitesse et pertinence
Les petits modèles de langage, ou « Small Language Models » (SLM) en anglais, représentent une alternative intéressante aux grands modèles de langage (LLM). Ils sont particulièrement attractifs en raison de leur rapidité d’exécution et de leurs faibles besoins en ressources matérielles. Leur temps d’évaluation des prompts et de génération des réponses est beaucoup plus court. Cela permet une intégration plus fluide dans les systèmes temps réel, les applications à faible consommation de ressources, et celles nécessitant des appels intensifs à ces modèles.
Leurs limites
Cependant, cette rapidité est souvent obtenue au prix de compromis sur la pertinence et la qualité des réponses. Ces compromis sont mesurés par des benchmarks tels que le MMLU (Massive Multitask Language Understanding) ou le MT-Bench (Multi-Turn Benchmark). Cela pose des défis importants pour les chercheurs et développeurs, qui cherchent à optimiser à la fois la rapidité et la pertinence.
Un compromis fondamental
Afin de tirer le meilleur parti du compromis décrit, lors de l’intégration du modèle de langage dans une architecture Produit, il est nécessaire de bien connaître les forces et faiblesses de chacun.
Afin de comparer les modèles de langage, nous nous sommes placés dans le cas d’usage où la vitesse de production de la réponse est primordiale.
Selon l’architecture matérielle et logicielle mise en œuvre lors du déploiement des modèles de langage ou selon le type de demande, les performances peuvent grandement varier. C’est pourquoi, l’étude que nous allons présenter n’est valable que pour l’architecture et pour les conditions pour laquelle elle a été construite.
Nous proposons une visualisation du compromis que nous avons obtenu pour les meilleurs petits modèles de langage disponibles à ce jour (le 28 octobre 2024).
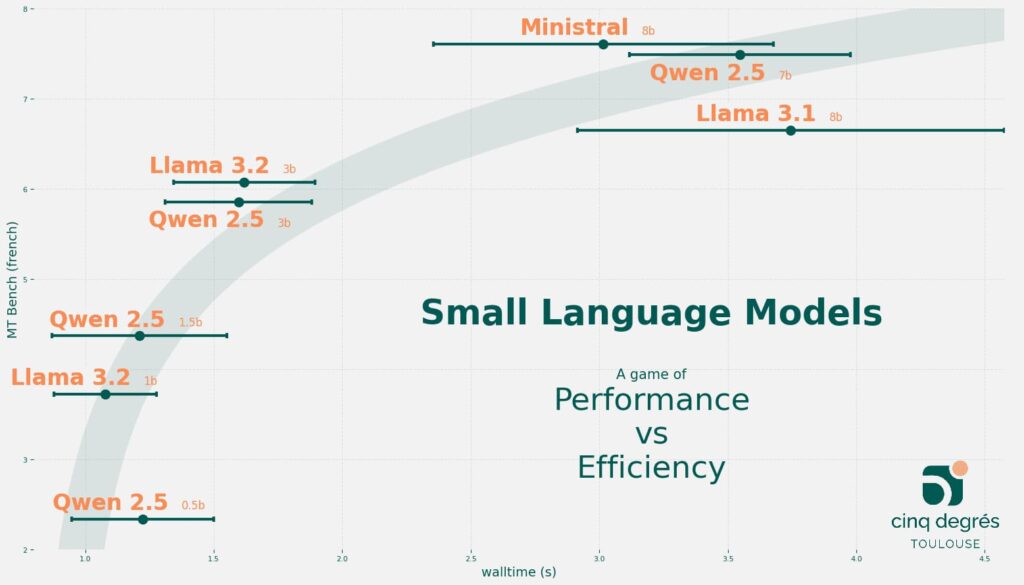
Le temps total représenté en abscisses ci-dessus correspond à la somme du temps d’évaluation du prompt et de la durée de la génération totale de la réponse au prompt.
De très nombreux facteurs peuvent influencer le temps total de réponse du modèle de langage tel que les ressources matérielles utilisées (CPU ou GPU), l’architecture logicielle, etc…
Pour connaître notre méthode de calcul et/ou obtenir ce type de graphique appliqué à votre cas d’usage spécifique, contactez-nous !
Une visualisation à adapter
Présentation du score MT-Bench
C’est un indicateur de performance utilisé pour évaluer la capacité des modèles de langage à gérer des conversations constituées de réponses successives. En d’autres termes, il mesure leur aptitude à comprendre le contexte et à fournir des réponses pertinentes sur plusieurs échanges consécutifs. Cela est essentiel pour des interactions naturelles et cohérentes. Ce benchmark prend en compte des critères comme la cohérence, la pertinence, et la capacité à maintenir le contexte de conversation.
Ses limites
Comme toutes les mesures de qualité des modèles de langage, le score MT-Bench a ses limites. Il est important de noter que certains modèles peuvent être davantage optimisés pour obtenir un meilleur score sur ce benchmark, sans que cela ne soit révélateur d’une meilleure qualité.
Nous avons utilisé le score MT-Bench spécifique aux échanges en Français. Cette mesure est souvent très pertinente au regard de nos applications actuelles. Votre cas d’utilisation possède certainement des spécificités précises qu’il conviendra de prendre en compte en adaptant la mesure de la pertinence.
En particulier, une piste d’optimisation réside dans l’adaptation des SLMs à des tâches spécifiques. Plutôt que d’utiliser des modèles génériques capables de répondre à tout type de requête, il est possible de se concentrer sur des modèles spécialisés sur des domaines restreints. Il est également possible d’adapter soi-même un modèle générique à un cas d’usage spécifique. Cela permet d’améliorer la pertinence des réponses dans un domaine particulier tout en maintenant une rapidité d’exécution élevée. Cette pratique s’appelle le fine-tuning.
D'autres pistes d'accélération
L’évolution des techniques de compression des modèles, telles que la quantification ou la distillation des connaissances, offre également des perspectives intéressantes. Ces techniques permettent de réduire la taille des modèles tout en conservant une partie significative de leur pertinence. La recherche dans ce domaine est en plein essor. Des avancées pourraient permettre de réduire l’écart entre la vitesse des SLMs et la pertinence des LLMs dans un futur proche.
Vous rencontrez des besoins similaires ? 5 Degrés peut vous accompagner sur vos différentes problématiques en Product Data.

Mathis GERMA
Consultant Data Scientist



